RNN은 sequence data를 처리하는 모델이다. sequence는 순서대로 처리해야 하는 것을 뜻하고, 이런 데이터에는 음성인식, 자연어 처리 등이 포함된다. 자연어의 경우 단어 하나만 안다고 해서 처리될 수 없고, 앞뒤 문맥을 함께 이해해야 해석이 가능하다.

순차적으로 들어오는 입력을 그림으로 표현하면 위와 같이 된다. 똑같은 모양이 오른쪽으로 무한하게 반복된다. 이걸 간단하게 표현하려고 하니까, 그림 왼쪽과 같은 형태가 된다. A에서 나온 화살표가 다시 A로 들어간다. 프로그래밍에서는 이런 걸 재진입(re-enterence) 또는 재귀(recursion)라고 부른다. 이쪽 세계에서는 recurrent라는 용어를 쓰고, "다시 현재"라는 뜻이고 정확하게는 "되풀이"라고 해석한다.

예문 : "what will the fat cat sit on"
예를 들어 훈련 코퍼스에 위와 같은 문장이 있다고 해보자.
RNN은 기본적으로 예측 과정에서 이전 시점의 출력을 현재 시점의 입력으로 한다. RNN은 what을 입력받으면, will을 예측하고 이 will은 다음 시점의 입력이 되어 the를 예측한다. 그리고 the는 또다시 다음 시점의 입력이 되고 해당 시점에서는 fat을 예측한다. 그리고 이 또한 다시 다음 시점의 입력이 된다. 결과적으로 세 번째 시점에서 fat은 앞서 나온 what, will, the라는 시퀀스로 인해 결정된 단어이며, 네 번째 시점의 cat은 앞서 나온 what, will, the, fat이라는 시퀀스로 인해 결정된 단어이다.
사실 위 과정은 훈련이 끝난 모델의 테스트 과정 동안(실제 사용할 때)의 이야기이다. 훈련 과정에서는 이전 시점의 예측 결과를 다음 시점의 입력으로 넣으면서 예측하는 것이 아니라, what will the fat cat sit on라는 훈련 샘플이 있다면, what will the fat cat sit 시퀀스를 모델의 입력으로 넣으면, will the fat cat sit on를 예측하도록 훈련된다. will, the, fat, cat, sit, on는 각 시점의 레이블이다.
이러한 RNN 훈련 기법을 교사 강요(teacher forcing)라고 한다. 교사 강요(teacher forcing)란, 테스트 과정에서 t 시점의 출력이 t+1 시점의 입력으로 사용되는 RNN 모델을 훈련시킬 때 사용하는 훈련 기법이다. 훈련할 때 교사 강요를 사용할 경우, 모델이 t 시점에서 예측한 값을 t+1 시점에 입력으로 사용하지 않고, t 시점의 레이블. 즉, 실제 알고있는 정답을 t+1 시점의 입력으로 사용한다.

훈련 과정 동안 출력층에서 사용하는 활성화 함수는 소프트맥스 함수이다. 그리고 모델이 예측한 값과 실제 레이블과의 오차를 계산하기 위해서 손실 함수로 크로스 엔트로피 함수를 사용한다. 이해를 돕기 위해 앞서 배운 NNLM의 그림과 유사한 형태로 RNN을 다시 시각화해보겠다.
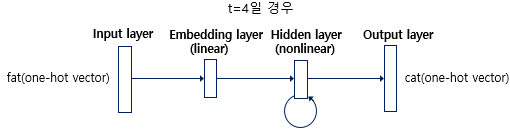
RNNLM의 구조를 보겠다. RNNLM은 위의 그림과 같이 총 4개의 층(layer)으로 이루어진 인공 신경망이다. 우선 입력층(input layer)을 보자. RNNLM의 현 시점(timestep)은 4로 가정한다. 그래서 4번째 입력 단어인 fat의 원-핫 벡터가 입력이 된다.
이제 출력층(Output layer)를 볼 것이다. 모델이 예측해야 하는 정답에 해당되는 단어 cat의 원-핫 벡터는 출력층에서 모델이 예측한 값의 오차를 구하기 위해 사용될 예정이다. 그리고 이 오차로부터 손실 함수를 사용해 인공 신경망이 학습을 하게 됩니다. 조금 더 구체적으로 볼 것이다.

현시점의 입력 단어의 원-핫 벡터 xtxt를 입력받은 RNN은 우선 임베딩층(embedding layer)을 지난다. 이 임베딩층은 기본적으로 NN 챕터에서 배운 투사층(projection layer)이다. NN 챕터에서는 룩업 테이블을 수행하는 층을 투사층라고 표현했지만, 이미 투사층의 결과로 얻는 벡터를 임베딩 벡터라고 부른다고 NNLM 챕터에서 학습했으므로, 앞으로는 임베딩 벡터를 얻는 투사층을 임베딩층(embedding layer)이라는 표현을 사용할 것이다.
단어 집합의 크기가 V일 때, 임베딩 벡터의 크기를 M으로 설정하면, 각 입력 단어들은 임베딩층에서 V × M 크기의 임베딩 행렬과 곱해진다. 여기서 V는 단어 집합의 크기를 의미한다. 만약 원-핫 벡터의 차원이 7이고, M이 5라면 임베딩 행렬은 7 × 5 행렬이 된다. 그리고 이 임베딩 행렬은 역전파 과정에서 다른 가중치들과 함께 학습됩니다. 이는 NN 챕터에서 이미 배운 개념이다.
임베딩층 : et=lookup(xt)et=lookup(xt)
여기서부터는 다시 RNN을 복습하는 것과 같다.
이 임베딩 벡터는 은닉층에서 이전 시점의 은닉 상태인 ht−1ht−1과 함께 다음의 연산을 하여 현재 시점의 은닉 상태 htht를 계산하게 된다.
은닉층 : ht=tanh(Wxet+Whht−1+b)ht=tanh(Wxet+Whht−1+b)
출력층에서는 활성화 함수로 소프트맥스(softmax) 함수를 사용하는데, V차원의 벡터는 소프트맥스 함수를 지나면서 각 원소는 0과 1 사이의 실수 값을 가지며 총합은 1이 되는 상태로 바뀐다. 이렇게 나온 벡터를 RNN의 t시점의 예측값이라는 의미에서 yt^yt^라고 합시다. 이를 식으로 표현하면 아래와 같다.
출력층 : yt^=softmax(Wyht+b)
'머신러닝 > 딥러닝을 이용한 자연어처리 입문' 카테고리의 다른 글
| Bag of Words(BoW) (0) | 2020.03.30 |
|---|---|
| 원-핫 인코딩(One-hot encoding) (0) | 2020.03.30 |
| 데이터의 분리(Splitting Data) (0) | 2019.11.19 |
| 불용어(Stopword) (0) | 2019.11.11 |
| 어간 추출(Stemming) and 표제어 추출(Lemmatization) (0) | 2019.11.01 |