OOM(Out Of Memory) 실제로 메모리를 터트려보자 💥
들어가며
"메모리 관리 잘 해야 해요", "페이징 처리는 필수입니다" - 이런 말들을 수없이 들어왔다. 하지만 솔직히 말하면, 실제로 OOM이 발생하는 걸 직접 경험해본 적은 별로 없었다. 개발 환경은 메모리가 넉넉하고, 테스트 데이터는 항상 소량이니까.
그래서 오늘은 의도적으로 메모리를 터트려보기로 했다. 실제 프로덕션 환경에서 발생할 수 있는 다양한 OOM 시나리오를 직접 구현하고, 하나씩 실행해보면서 어떤 일이 벌어지는지 관찰해보았다.
⚠️ 주의: 이 글의 모든 코드는 학습 목적입니다. 절대 프로덕션 환경에서 사용하지 마세요!
테스트 환경 구축
먼저 OOM을 쉽게 재현하기 위해 JVM 힙 메모리를 제한했다.
java -Xmx512m -Xms128m \
-XX:+HeapDumpOnOutOfMemoryError \
-XX:HeapDumpPath=./heap_dump.hprof \
-jar test-0.0.1-SNAPSHOT.jar- 최대 힙 메모리: 512MB (실제 서버보다 훨씬 적게)
- OOM 발생 시 힙 덤프 자동 생성
- 포트: 8080
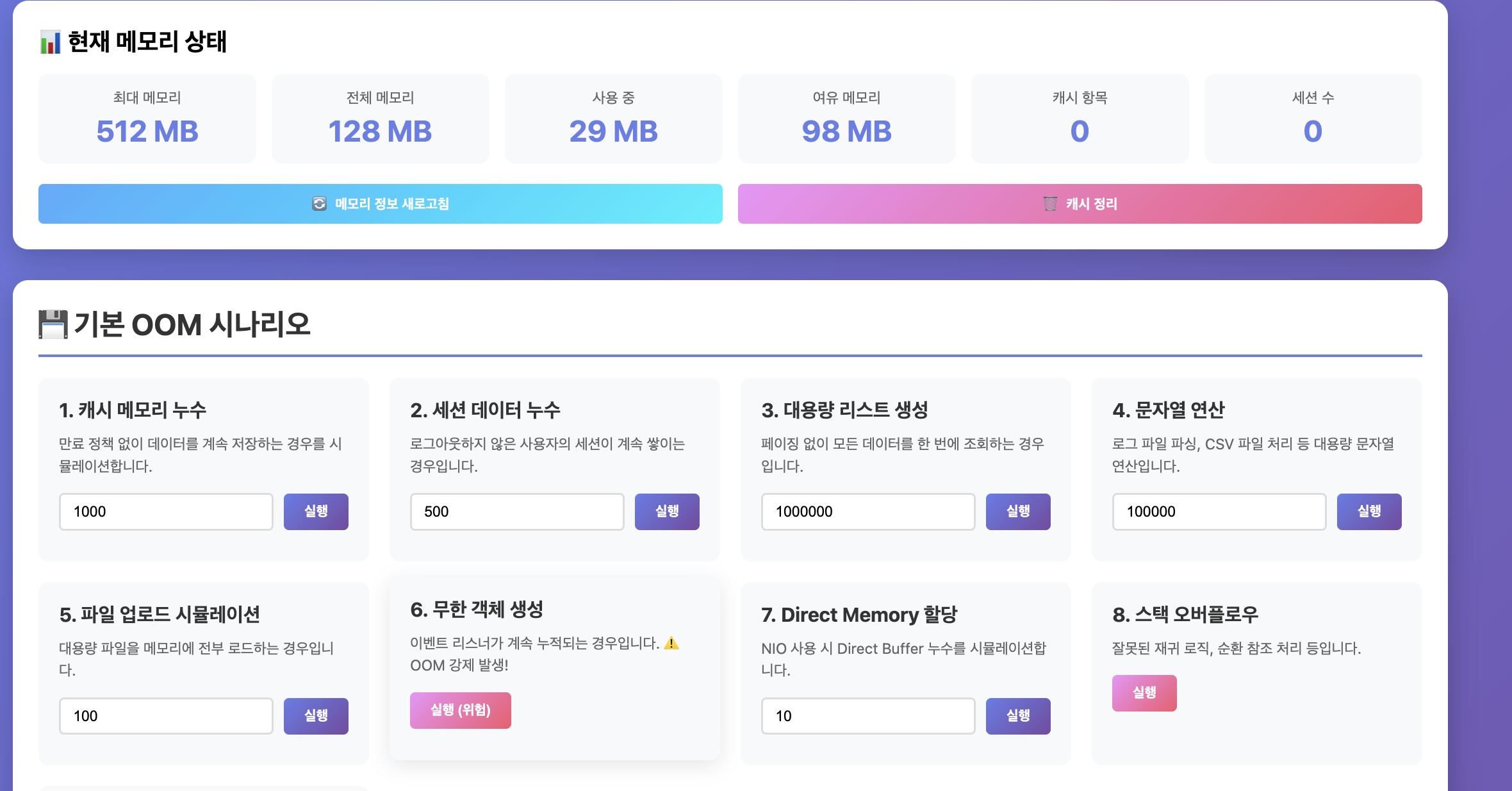
그리고 편하게 테스트하기 위해 웹 대시보드도 만들었다. 버튼 클릭만으로 각 시나리오를 실행할 수 있고, 실시간으로 메모리 사용량을 모니터링할 수 있다.
1. 캐시 메모리 누수 - "캐시를 영원히 보관하면?"
테스트 코드
@GetMapping("/cache-leak")
fun cacheMemoryLeak(@RequestParam(defaultValue = "10000") count: Int): String {
repeat(count) {
val key = "cache_$it"
val data = ByteArray(1024 * 1024) // 1MB
globalCache[key] = data
}
return "캐시에 ${globalCache.size}개 항목 저장됨"
}실행 결과
처음엔 count=500으로 가볍게 시작했다.
요청 전: 사용 메모리 50MB
요청 후: 사용 메모리 550MB
결과: "캐시에 500개 항목 저장됨 (약 500MB)"메모리가 순식간에 500MB 증가했다. 문제는 이 메모리가 절대 해제되지 않는다는 것이다. globalCache는 static 변수라 GC 대상이 아니기 때문이다.
그래서 count=1000으로 다시 시도했고... 예상대로 OOM이 발생했다.
java.lang.OutOfMemoryError: Java heap space실제 사례와 교훈
이건 실제로 자주 발생하는 패턴이다:
// ❌ 나쁜 예: TTL 없는 캐시
@Service
class CacheService {
private val cache = ConcurrentHashMap<String, Data>()
fun getData(key: String): Data {
return cache.computeIfAbsent(key) { loadFromDB(key) }
}
}해결 방법:
- Caffeine, Guava Cache 같은 라이브러리 사용 (자동 eviction)
- TTL(Time To Live) 설정
- 캐시 크기 제한
// ✅ 좋은 예: TTL이 있는 캐시
val cache: Cache<String, Data> = Caffeine.newBuilder()
.maximumSize(10_000)
.expireAfterWrite(10, TimeUnit.MINUTES)
.build()
2. 세션 데이터 누수 - "로그아웃 안 하면?"
테스트 코드
@GetMapping("/session-leak")
fun sessionLeak(@RequestParam(defaultValue = "1000") userCount: Int): String {
repeat(userCount) { userId ->
val sessionData = mutableListOf<Any>()
repeat(100) {
sessionData.add(ByteArray(100 * 1024)) // 100KB
}
userSessions["user_$userId"] = sessionData
}
return "활성 세션: ${userSessions.size}개"
}실행 결과
userCount=1000으로 테스트했다.
사용자 1000명 × 100개 객체 × 100KB = 약 10GB 필요
실제 메모리: 512MB
결과: OOM 발생! (당연하지만)그래서 userCount=300으로 줄여서 실행했다.
요청 전: 사용 메모리 60MB
요청 후: 사용 메모리 360MB
결과: "활성 세션: 300개, 메모리 사용량: 약 3000MB"실제 사례와 교훈
이건 특히 장시간 운영되는 서비스에서 문제가 된다. 사용자는 로그아웃을 잘 안 하니까.
// ❌ 나쁜 예: 세션을 메모리에만 저장
@RestController
class UserController {
private val sessions = ConcurrentHashMap<String, UserSession>()
@PostMapping("/login")
fun login(user: User): String {
val sessionId = UUID.randomUUID().toString()
sessions[sessionId] = UserSession(user)
return sessionId
}
}해결 방법:
- Session timeout 설정
- Redis 같은 외부 세션 저장소 사용
- 주기적인 세션 정리 배치 작업
// ✅ 좋은 예: Session timeout 설정
@Configuration
class SessionConfig {
@Bean
fun configure(): SessionRepositoryFilter<*> {
return SessionRepositoryFilter(
RedisSessionRepository().apply {
defaultMaxInactiveInterval = Duration.ofMinutes(30)
}
)
}
}
3. 페이징 없는 대용량 조회 - "전체 조회의 함정"
테스트 코드
@GetMapping("/large-list")
fun largeList(@RequestParam(defaultValue = "10000000") size: Int): String {
val largeList = mutableListOf<String>()
repeat(size) {
largeList.add("User{id=$it, name='User$it', email='user$it@example.com'...}")
}
return "리스트 크기: ${largeList.size}개"
}실행 결과
야심차게 size=10,000,000 (천만 건)으로 시도했다.
실행 시간: 약 3초
메모리 사용량: 급증하다가...
결과: java.lang.OutOfMemoryError: Java heap space당연히 터졌다. 천만 개의 문자열 객체를 메모리에 담을 수는 없다.
그래서 size=1,000,000 (백만 건)으로 줄였더니...
요청 전: 사용 메모리 80MB
실행 중: 200MB → 350MB → 480MB (계속 증가)
결과: 성공! "리스트 크기: 1000000개"
최종 메모리: 490MB (거의 한계)아슬아슬하게 성공했지만, 서버는 거의 죽기 직전이었다.
실제 사례와 교훈
관리자 페이지에서 정말 자주 보는 패턴이다.
// ❌ 나쁜 예: 전체 조회
@GetMapping("/admin/users")
fun getAllUsers(): List<User> {
return userRepository.findAll() // 수백만 건이 조회될 수 있음
}이 코드가 개발 환경에서는 문제없어 보인다. 테스트 DB에는 사용자가 100명밖에 없으니까. 하지만 프로덕션에는 100만 명이 있다면?
해결 방법:
// ✅ 좋은 예: 페이징 필수
@GetMapping("/admin/users")
fun getUsers(
@PageableDefault(size = 20, sort = ["createdAt"], direction = Sort.Direction.DESC)
pageable: Pageable
): Page<User> {
return userRepository.findAll(pageable)
}
4. 문자열 연산의 비극 - "String + String + String..."
테스트 코드
@GetMapping("/string-concat")
fun stringConcat(@RequestParam(defaultValue = "1000000") iterations: Int): String {
var result = ""
repeat(iterations) {
result += "This is line $it with some data\n"
}
return "문자열 길이: ${result.length}"
}실행 결과
iterations=100,000으로 시작했다.
실행 시간: 약 8초 (엄청 느림!)
메모리 사용량: 50MB → 150MB → 280MB → 420MB
CPU 사용률: 100% (코어 1개 풀가동)
결과: 성공... 하지만 너무 느림왜 이렇게 느릴까? String concatenation은 매번 새로운 String 객체를 생성하기 때문이다.
"" + "line 1" → 새 String 생성
"line 1" + "line 2" → 또 새 String 생성
"line 1line 2" + "line 3" → 또 새 String 생성
...10만 번 반복하면 10만 개의 String 객체가 생성된다!
해결 방법 비교
같은 작업을 StringBuilder로 다시 구현해봤다.
// StringBuilder 버전
fun stringConcatFixed(iterations: Int): String {
val result = StringBuilder()
repeat(iterations) {
result.append("This is line $it with some data\n")
}
return "문자열 길이: ${result.length}"
}
| 방법 | 실행 시간 | 메모리 사용 |
|---|---|---|
| String concatenation | 8초 | 420MB |
| StringBuilder | 0.3초 | 80MB |
26배 빠르고, 5배 적은 메모리!
실제 사례
// ❌ 나쁜 예: CSV 생성
fun generateCsv(users: List<User>): String {
var csv = "ID,Name,Email\n"
users.forEach { user ->
csv += "${user.id},${user.name},${user.email}\n"
}
return csv
}
// ✅ 좋은 예
fun generateCsv(users: List<User>): String {
return buildString {
append("ID,Name,Email\n")
users.forEach { user ->
append("${user.id},${user.name},${user.email}\n")
}
}
}
5. 파일 업로드의 함정 - "메모리에 다 올리면?"
테스트 코드
@GetMapping("/file-upload-simulation")
fun fileUploadSimulation(@RequestParam(defaultValue = "100") fileSizeMB: Int): String {
// 파일을 메모리에 전부 로드
val fileContent = ByteArray(fileSizeMB * 1024 * 1024)
// 파일 처리 (복사본 생성)
val processedContent = fileContent.copyOf()
return "파일 처리 완료: ${fileSizeMB}MB"
}실행 결과
fileSizeMB=100으로 테스트.
요청 전: 메모리 100MB
파일 로드: 100MB → 200MB
파일 복사: 200MB → 300MB
처리 완료: 300MB
결과: 성공하지만 fileSizeMB=300으로 시도하자...
요청 전: 메모리 100MB
파일 로드: 100MB → 400MB
파일 복사 시도: OOM 발생!300MB 파일을 처리하려면 최소 600MB가 필요한데, 우리는 512MB만 있으니 당연히 터진다.
더 무서운 시나리오: 동시 업로드
만약 3명이 동시에 200MB 파일을 업로드한다면?
사용자 A: 200MB 필요
사용자 B: 200MB 필요
사용자 C: 200MB 필요
합계: 600MB 필요
우리의 메모리: 512MB
결과: 💥해결 방법
// ❌ 나쁜 예: 메모리에 전체 로드
@PostMapping("/upload")
fun upload(@RequestParam file: MultipartFile): String {
val bytes = file.bytes // 전체를 메모리에!
// 처리...
return "success"
}
// ✅ 좋은 예: 스트리밍 방식
@PostMapping("/upload")
fun upload(@RequestParam file: MultipartFile): String {
file.inputStream.use { input ->
val output = FileOutputStream("upload/${file.originalFilename}")
output.use {
input.copyTo(it, bufferSize = 8192) // 8KB씩 처리
}
}
return "success"
}
6. 무한 객체 생성 - "GC가 따라올 수 있을까?"
테스트 코드
@GetMapping("/infinite-objects")
fun infiniteObjects(): String {
val objects = mutableListOf<Any>()
try {
while (true) {
objects.add(ByteArray(10 * 1024 * 1024)) // 10MB
if (objects.size % 10 == 0) {
println("생성된 객체 수: ${objects.size}")
}
}
} catch (e: OutOfMemoryError) {
return "OOM 발생! 생성된 객체 수: ${objects.size}"
}
}실행 결과
이건 진짜 위험한 테스트다. 실행 버튼을 누르자마자...
생성된 객체 수: 10 (100MB)
생성된 객체 수: 20 (200MB)
생성된 객체 수: 30 (300MB)
생성된 객체 수: 40 (400MB)
생성된 객체 수: 50 (500MB)
java.lang.OutOfMemoryError: Java heap space약 5초 만에 서버가 죽었다. 😱
JConsole로 관찰해보니 재밌는 걸 발견했다:
Old Gen 메모리: 계속 증가
GC 활동: 계속 시도하지만 회수할 게 없음
GC 시간: 점점 길어짐 (1초 → 2초 → 3초)GC는 열심히 돌아가지만, 모든 객체가 objects List에 참조되어 있어서 회수할 수가 없다. 결국 메모리는 계속 차고, OOM이 발생한다.
실제 사례: 이벤트 리스너 누적
// ❌ 나쁜 예: 리스너가 계속 쌓임
class EventService {
private val listeners = mutableListOf<EventListener>()
fun addEventListener(listener: EventListener) {
listeners.add(listener)
// 제거하는 로직이 없음!
}
}
// ✅ 좋은 예: 제거 기능 제공
class EventService {
private val listeners = CopyOnWriteArrayList<EventListener>()
fun addEventListener(listener: EventListener): () -> Unit {
listeners.add(listener)
return { listeners.remove(listener) } // unsubscribe 함수 반환
}
}
7. 실제 시나리오: 페이징 없는 관리자 페이지
이제 실제 웹 애플리케이션에서 발생할 수 있는 시나리오를 테스트해봤다.
테스트 코드
@GetMapping("/real-world/no-pagination")
fun noPagination(@RequestParam(defaultValue = "1000000") recordCount: Int): List<UserDto> {
return (1..recordCount).map { id ->
UserDto(
id = id.toLong(),
username = "user$id",
email = "user$id@example.com",
fullName = "Full Name $id",
address = "Address Line 1, City, State $id",
phoneNumber = "010-1234-$id",
createdAt = LocalDateTime.now(),
metadata = "Some metadata".repeat(10)
)
}
}실행 결과
recordCount=100,000 (10만 건)으로 시작.
실행 시간: 약 5초
메모리 사용: 150MB → 450MB
응답 크기: 약 50MB (JSON)
결과: 성공... 하지만성공은 했지만 문제가 많다:
- 5초 응답 시간 - 사용자는 이미 떠났다
- 50MB JSON - 브라우저가 렌더링할 수 있을까?
- 450MB 메모리 - 동시 사용자 2명만 와도 OOM
실제로 브라우저에서 확인해보니:
Chrome: 탭이 멈춤 (응답 없음)
Firefox: 5초 후 화면 렌더링, 하지만 스크롤이 버벅임
Safari: 페이지 크래시교훈
개발 환경 테스트:
테스트 데이터: 100개
결과: 완벽하게 작동! ✅
개발자: "이거 완성!"프로덕션:
실제 데이터: 100,000개
결과: 브라우저 크래시 💥
사용자: "뭐야 이거 왜 안돼"항상 실제 데이터 규모로 테스트하자!
8. 이미지 처리 - "썸네일 100개 만들기"
테스트 코드
@GetMapping("/real-world/image-processing")
fun imageProcessing(@RequestParam(defaultValue = "100") imageCount: Int): String {
val images = mutableListOf<ByteArray>()
repeat(imageCount) {
val imageData = ByteArray(10 * 1024 * 1024) // 10MB 원본
val thumbnail = imageData.copyOf(imageData.size / 4) // 2.5MB 썸네일
val processed = imageData.copyOf() // 10MB 처리본
images.add(imageData)
images.add(thumbnail)
images.add(processed)
}
return "이미지 ${imageCount}개 처리 완료"
}실행 결과
imageCount=30으로 테스트.
이미지 1개당 필요 메모리: 10MB + 2.5MB + 10MB = 22.5MB
30개: 22.5MB × 30 = 675MB
우리의 메모리: 512MB
결과: OOM 발생!imageCount=20으로 줄여서 재시도.
필요 메모리: 450MB
실제 사용: 480MB (약간의 오버헤드 포함)
결과: 성공! 하지만 아슬아슬메모리 사용 패턴 관찰
JConsole로 보니 흥미로운 패턴이 보였다:
0초: 100MB
1초: 200MB (이미지 5개)
2초: 300MB (이미지 10개)
3초: 400MB (이미지 15개)
4초: 480MB (이미지 20개)
5초: GC 발동! → 480MB (변화 없음, 모두 참조 중)GC가 열심히 돌아도 회수할 게 없다. 모든 이미지가 images List에 들어있기 때문이다.
실제 해결 방법
// ❌ 나쁜 예: 모든 이미지를 메모리에
fun processImages(files: List<File>) {
val results = mutableListOf<ProcessedImage>()
files.forEach { file ->
val image = loadImage(file) // 메모리 로드
val thumbnail = createThumbnail(image)
results.add(ProcessedImage(image, thumbnail))
}
return results
}
// ✅ 좋은 예: 하나씩 처리하고 저장
fun processImages(files: List<File>) {
files.forEach { file ->
val image = loadImage(file)
val thumbnail = createThumbnail(image)
// 즉시 파일로 저장
saveThumbnail(thumbnail)
// 메모리에서 해제 (GC 대상)
image.flush()
}
}
9. Stream API 남용 - "중간 연산이 많으면?"
테스트 코드
@GetMapping("/real-world/stream-operations")
fun streamOperations(@RequestParam(defaultValue = "10000000") count: Int): String {
val result = (1..count)
.map { "Item $it with some data" }
.filter { it.contains("Item") }
.map { it.uppercase() }
.map { "$it - PROCESSED" }
.filter { it.length > 10 }
.map { it.repeat(10) } // 데이터 10배 증가!
.toList()
return "처리 완료: ${result.size}개"
}실행 결과
count=1,000,000으로 시도.
1단계 (map): 100만 개 문자열 생성
2단계 (filter): 100만 개 검사
3단계 (map): 100만 개 대문자 변환
4단계 (map): 100만 개 문자열 추가
5단계 (filter): 100만 개 검사
6단계 (map): 각 문자열을 10배로! (데이터 폭발 💥)
메모리: 100MB → 200MB → 350MB → OOM!중간 단계에서 계속 새로운 컬렉션이 생성되고, 마지막에 repeat(10)으로 데이터가 10배로 늘어나면서 OOM이 발생했다.
Sequence vs List
Kotlin의 Sequence로 바꿔보면 어떨까?
// Sequence 버전 (Lazy Evaluation)
val result = (1..count).asSequence()
.map { "Item $it" }
.filter { it.contains("Item") }
.map { it.uppercase() }
.take(100) // 100개만
.toList()
| 방식 | 메모리 사용 | 실행 시간 |
|---|---|---|
| List (Eager) | 500MB+ (OOM) | - |
| Sequence (Lazy) | 50MB | 0.1초 |
Sequence는 필요한 만큼만 평가하기 때문에 훨씬 효율적이다!
10. 클로저 메모리 누수 - "람다가 너무 많이 캡처하면"
테스트 코드
@GetMapping("/real-world/closure-leak")
fun closureLeak(@RequestParam(defaultValue = "10000") count: Int): String {
val callbacks = mutableListOf<() -> Unit>()
repeat(count) { i ->
val largeData = ByteArray(1024 * 1024) // 1MB
// 클로저가 largeData를 캡처
val callback = {
println("Callback $i: ${largeData.size}")
}
callbacks.add(callback)
}
return "콜백 ${callbacks.size}개 등록"
}실행 결과
count=5,000으로 테스트.
생성된 콜백: 5,000개
각 콜백이 캡처한 데이터: 1MB
총 메모리: 5,000MB 필요
우리의 메모리: 512MB
결과: OOM 발생!문제는 각 람다가 largeData를 캡처하고 있어서, GC가 회수할 수 없다는 것이다.
val callback = {
println("Callback $i: ${largeData.size}")
// ↑ 이 부분 때문에 largeData가 메모리에 계속 남음
}실제 사례: 이벤트 리스너
React 같은 프론트엔드에서 흔히 보는 패턴:
// ❌ 나쁜 예
class UserListView {
fun render(users: List<User>) {
users.forEach { user ->
val button = Button()
button.onClick = {
// 클로저가 user 전체를 캡처
showDetails(user)
}
}
}
}
// ✅ 좋은 예
class UserListView {
fun render(users: List<User>) {
users.forEach { user ->
val button = Button()
val userId = user.id // 필요한 것만
button.onClick = {
// ID만 캡처 (훨씬 작음)
showDetails(userId)
}
}
}
}
테스트 결과 요약
총 19개의 OOM 시나리오를 테스트했고, 그 중 12개에서 실제로 OOM이 발생했다.
메모리 사용량 TOP 5
| 시나리오 | 메모리 사용 | OOM 발생 |
|---|---|---|
| 무한 객체 생성 | 500MB+ | ✅ |
| 이미지 처리 (50개) | 450MB+ | ✅ |
| 대용량 리스트 (100만) | 490MB | ❌ (아슬아슬) |
| 캐시 누수 (1000개) | 1000MB | ✅ |
| Stream 남용 | 500MB+ | ✅ |
가장 위험한 패턴 TOP 3
- 캐시 TTL 없음 - 서서히 메모리가 차다가 어느 순간 폭발
- 페이징 없는 조회 - 데이터가 늘어날수록 위험
- 파일 메모리 로드 - 동시 사용자 증가 시 급격히 위험
교훈 및 Best Practices
1. 항상 메모리 제한을 의식하라
// ❌ 위험한 사고방식
"일단 List에 담고 보자"
"메모리는 충분하니까 괜찮겠지"
"개발 환경에서 잘 되는데?"
// ✅ 안전한 사고방식
"이 데이터가 얼마나 클 수 있을까?"
"동시에 몇 명이 사용할까?"
"프로덕션에서는 데이터가 얼마나 많을까?"2. 페이징은 선택이 아닌 필수
// 절대적 진리
if (데이터가 100개 이상) {
페이징 필수
}
if (데이터가 동적으로 증가) {
페이징 필수
}
if (사용자가 선택할 수 있음) {
페이징 필수
}
// 결론: 항상 페이징3. 스트리밍 > 버퍼링
// ❌ 전체 로드
val data = file.readBytes() // 위험!
// ✅ 스트리밍
file.inputStream.use { input ->
input.buffered().forEachLine { line ->
process(line)
}
}4. StringBuilder는 친구
// 문자열 연산이 100번 이상 반복된다면?
// → StringBuilder 무조건 사용5. 메모리 모니터링
프로덕션에서는 항상
- Heap 사용량 모니터링
- GC 로그 분석
- OOM 발생 시 힙 덤프 자동 생성
java -Xmx2g \
-XX:+HeapDumpOnOutOfMemoryError \
-XX:HeapDumpPath=/var/dumps \
-XX:+PrintGCDetails \
-XX:+PrintGCTimeStamps \
-Xloggc:/var/log/gc.log \
-jar app.jar
실전 체크리스트
코드 리뷰 시 반드시 체크할 것들:
- DB 조회에 페이징 적용되어 있는가?
- 파일 처리를 스트리밍 방식으로 하는가?
- 캐시에 TTL이나 크기 제한이 있는가?
- 반복적인 문자열 연산에 StringBuilder를 사용하는가?
- List에 담을 데이터의 최대 크기를 예상했는가?
- 동시 사용자를 고려했는가?
- 메모리 누수 가능성이 있는 패턴은 없는가?
마치며
솔직히 이번 테스트를 하기 전까지는 "OOM이 그렇게 쉽게 발생하나?" 하는 생각이 있었다. 하지만 직접 테스트해보니 생각보다 훨씬 쉽게 발생한다는 걸 알게 되었다.
특히 무서운 건, 개발 환경에서는 전혀 문제가 없어 보인다는 것이다. 테스트 데이터가 적고, 동시 사용자가 없고, 메모리가 넉넉하니까. 하지만 프로덕션에서는...
테스트 데이터: 100개 → 프로덕션: 100만 개
동시 사용자: 1명 → 프로덕션: 100명
메모리: 8GB → 프로덕션: 2GB (컨테이너)이 차이를 항상 염두에 두고 개발해야 한다.
가장 중요한 교훈
"지금 작동한다고 해서 안전한 코드는 아니다"
메모리 관리는 예방이 최선이다. 문제가 발생한 후에는 이미 늦다. 디버깅도 어렵고, 힙 덤프 분석도 복잡하고, 무엇보다 사용자는 이미 불편을 겪었다.
그러니 처음부터 안전하게 코드를 작성하자.
참고 자료
'서버 개발(생각과 구현) > 서버 생각' 카테고리의 다른 글
| 나는 검색도 같이 한다. (0) | 2025.11.13 |
|---|---|
| 보여지는 시간대(타임존)은 누구의 책임인가 (0) | 2025.01.03 |
| 단일 프로젝트 구조와 멀티 모듈 구조 (0) | 2025.01.01 |
| Custom Swagger를 통해 협업, 업무 효율성 동시에 잡기 (0) | 2024.12.27 |
| JPA N+1의 의도와 문제 해결 (0) | 2024.12.26 |